随着用户获取信息的方式差异化,音频产品因为使用场景多元、伴随性和碎片化,在当下快节奏的社会中,受到越来越多的用户欢迎。iimedia research数据显示,2018年在线音频用户规模增速达22.1%,2018年用户数量达到4.25亿。
用户的快速发展,也伴随着低俗、色情内容在这些音频平台上蔓延。最典型的就是去年6月份,全国“扫黄打非”办公室约谈多家网站负责人,要求各平台大力清理涉色情低俗问题的asmr内容,加强对相关内容的监管和审核。
然而对音频的内容审核存在多个难点,比如说语音识别和声纹识别难、数据标注成本大等,给很多音视频平台的发展带来困扰。为此,网易易盾在2018年推出了音频检测服务,通过业内领先的语音识别技术,精确、高效地帮助音频平台分析和识别出各类违规音频。
最近,网易易盾又对音频检测服务进行迭代升级,在点播音频过检的基础上,开始支持直播音频,实现实时音频检测。
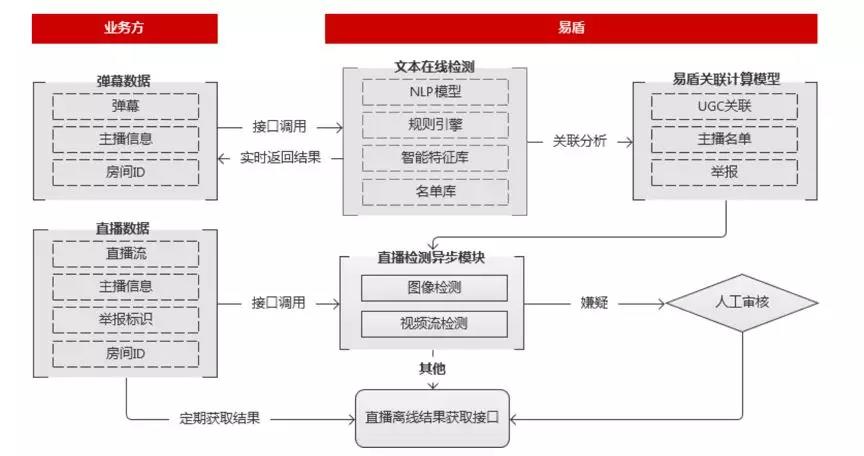
除了支持实时检测外,本次直播音频检测还新增了结合场景的关联分析:能够根据弹幕、主播等信息维度,通过文本nlp模型、规则引擎、智能特征库等技术实现提前风险预判,更准确地返回审核结果。
高准确性的背后是网易易盾在声纹检测的背景环境和数据多样性上下足了功夫。据网易易盾算法专家姚泽平介绍,音频实时检测上最大的难题是背景噪声的动态变化,导致违规音频和背景噪声的重叠更加复杂,让模型分类难度变大。
“我们做了两方面工作,一方面是人工地构造一些特定场景的背景噪声,和违禁数据相混合,用这些数据训练模型,提高模型对动态背景环境的鲁棒性。另一方面是,通过对数据进行归一化的方法,减少客观因素对模型分类造成的影响。”姚泽平说到。
领先技术的应用,使得网易易盾音频检测能够高效识别色情语音、渉政、娇喘语音、asmr、谩骂等违规语音;在应用场景上,也能完美覆盖im通讯、点播音频和直播音频。