asru 2019中英混杂语音识别挑战赛最终结果近日出炉,凭借语音识别系统建设的积累及针对transformer网络的优化,网易杭州研究院(简称网易杭研)团队在端到端语音识别赛道夺得冠军。网易杭研人工智能部语音算法专家刘东认为,这表明网易杭研在基于端到端框架的中英混杂语音识别领域达到业界领先水平,网易业务发展再获ai新动能。
asru2019中英混杂语音识别挑战赛由数据堂、西北工业大学和中国计算机学会联合主办,旨在促进国内外语种混杂语音识别领域的研究,获奖团队将参加2019年12月新加坡asru2019会议(语音和语言领域的旗舰技术活动)的颁奖与技术交流活动。比赛吸引了国内及新加坡近40个团队参加,其中包括很多语音识别技术声名在外的企业和高校。
1.数据驱动破语种混杂难题,网易杭研端到端识别夺冠
人类实际日常交流中经常会有中文语境下英文单词夹杂的现象,这在学术上称为语种混杂(code-switch),是当前语音识别技术面临的重要挑战之一。其技术难点主要表现为:嵌入语受主体语影响形成的非母语口音现象严重、不同语言音素构成之间的差异给混合声学建模带来巨大困难、带标注的混合语音训练数据极其稀缺。
刘东介绍,传统语音算法在不同语种识别基础建模单元上,语言学信息是不一样的,如汉语是基于拼音的声母韵母、英语则是英文的音素,这种技术架构对指定语种的语言学知识依赖较大,也难以扩展到多语种识别。网易杭研智能语音团队近期重点研发的端到端语音识别系统,用统一的网络进行建模,不需要人工进行建模单元选择与发音词典编辑等工作,更多依赖于数据而非语言学信息。
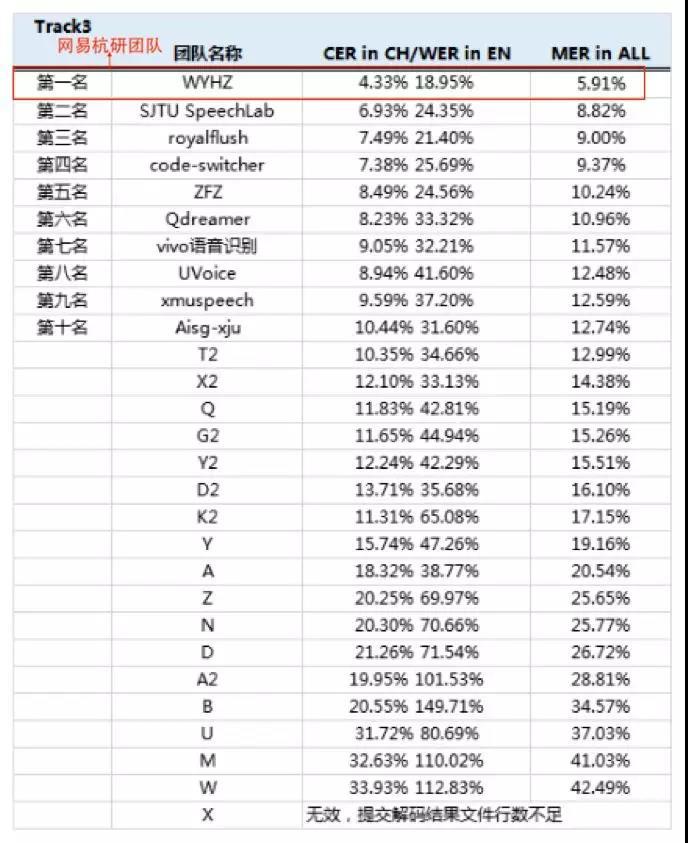
网易杭研采用基于注意力(attention)机制的transformer网络结构,并做了各种细节优化,如引入多任务学习机制(multi-task learning),在编码端加入ctc准则,在解码端加入逐字的语种判别准则,以及训练数据的频谱加噪、大batch训练、学习率调整等,突破了各种技术挑战,在端到端语音识别赛道提供的数据集上实现了5.91%的综合错误率(mix error rate),从28个团队中脱颖而出,成绩大幅领先第二名(8.82%)。
数据驱动的技术路线也意味着对数据和计算的更高需求,如以前需要几千数据跑出的结果,现在可能需要几万数据。得益于团队在底层平台优化方面的积累,包括分布式训练框架和推理引擎,都有比较成熟的方案,这并未对网易杭研造成困扰。“底层平台优化靠的是长期的积累,这对网易集团降低智能语音应用成本至关重要。”刘东说,生产级语音识别系统的建设,需要团队既懂网络架构,又懂底层优化。
2.端到端识别将迎大规模应用,助力业务国际化
网易杭研发力端到端语音识别的目标,是打破传统技术局限,实现一套易于扩展的语音识别系统,能够快速识别各种各样的语种,满足网易业务发展尤其是国际化的需求。例如,一些全球同服的游戏,用户语音转换文字时,会同时有中英日韩多种语言需要支持;语音翻译应用,目前需要先选择语种再说话,实际应用中容易选错导致无法识别……这些实际的业务场景,都在呼唤多语种混合识别系统的诞生、成熟。
端到端语音识别系统能够减少对语言学知识的依赖,突破语种支持的限制,将现有成果很快迁移到其他语言上,成为了网易杭研的选择。此次端到端语音识别赛道的设置,正好可以检验团队的阶段成果。也正因为如此,网易杭研只参加了第三赛道的比赛。但结果让团队感到满意。刘东表示,算法层面,杭研中英混合识别在基础框架研发、调优已经基本完成,系统正在逐步完善和优化之中,目前已有业务在测试。当然,要实现大规模应用还有一些细节需要优化,包括针对一些特定场景的数据收集、模型微调等,这需要在业务实践中调整。
未来数字化经济的发展要从拼本土走到拼世界,网易游戏、教育等业务已在国际化探索方面取得初步进展,网易杭研的这项创新技术,预计将成为网易发展的一个重要助力。
据悉,网易杭研语音识别服务自2014年首次上线以来,多年来已为游戏、教育、音乐、传媒、企业服务领域的多个业务提供持续稳定的600全讯开户送白菜的服务支持,在通用领域的识别准确率达到95%以上,尤其在电商、电话客服等领域,经过针对性的定制优化,识别性能达到行业领先水平。在业务方组织的各项对比测试中,综合性能比肩甚至超过行业标杆企业。
本文来源:网易杭州研究院