汪源认为,当前人工智能技术发展分为三个层次,第一个层次是底层的平台层,包括深度学习平台。中间的层次是能力层,云计算、自然语言处理、视觉处理等技术处于能力层中。第三个层次是应用层,人工智能各种落地的应用产品在这一层次中。中间的能力层是当前人工智能公司主要的发力点。
对于人工智能在工程领域应用的看法,他认为所有的人工智能都是从语音识别,到图像识别再到自然语言处理。在实际应用场景中,一个通用的处理技术,比如语音识别,在应用到特定场景里的时候,可能达不到较好的使用效果。在自然语言处理方面,以客服机器人举例,基于传统知识库的客服机器人不是真正意义上的人工智能至尊全讯大全官网的解决方案,只是通过问题来检索知识库。客服机器人要解决多轮对话的问题,涉及到m的机制、a的机制,同时也要解决知识领域的一些问题,客服机器人实际上是知识库的动态学习,以上这些机制是为了提高知识库学习的效率。
汪源表示,图像识别的应用场景同文本识别的原理相似,传统方法在图片过滤应用中解决不了的问题,通过深度学习的方式可以做到非常精准。以网易的图片鉴黄为例,之前需要一些鉴黄师手动筛选,现在依靠深度学习的算法能够做到99.8%的准确率。

以下为演讲实录
刚才吴院长高瞻远瞩,然后讲了很多人工智能激动人心的前沿的一些课题。网易作为一家公司,比较侧重于注重技术跟业务相结合,所以我讲的东西可能会比较落地、比较实际,没有特别高大上的一些话题,我们可能会先树立一些小目标,先解决一些小问题。
先总体上给大家介绍一下网易在人工智能做的相关工作,分成五六个部分。
第一个是介绍一下网易杭州研究院的定位。研究院是06年成立,我刚好在成立的时候进入研究院。网易杭州研究院负责创新业务的孵化,同时也负责给整个公司提供公共的基础平台的支撑。这个机制还是比较特殊的,在国内互联网企业中,唯有网易杭州研究院兼具产品、运维和公共技术平台三重职能和唯一性,为互联网技术研究提供了得天独厚的条件。
对于我来讲,我要为公司的业务提供非常多的技术支撑,从高大上的人工智能,到不太高大上的质量保障都得做。质量保障我们也跟人工智能做了相应的很好的结合。
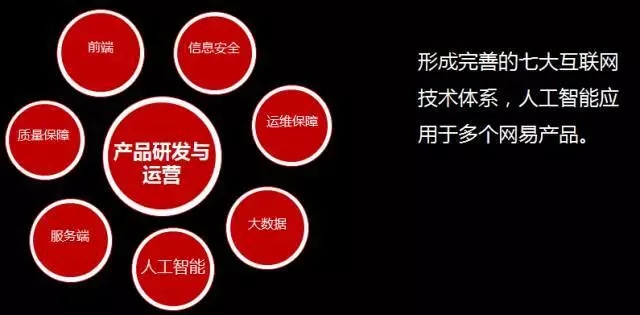
整个网易杭州研究院主要负责构建的是互联网的技术体系,七大技术体系里面其中一个就是多媒体以及人工智能方向,所以今天讲的主要是人工智能方向我们做的一些工作。
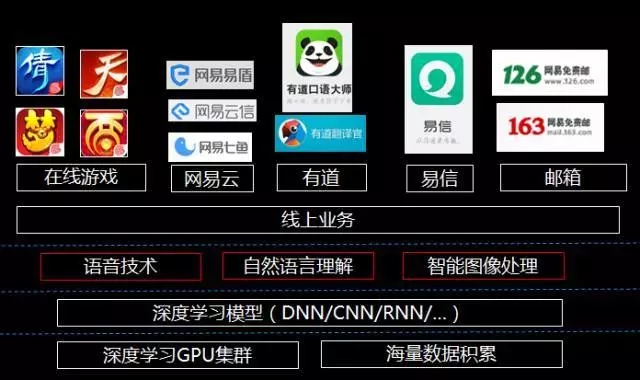
这张图可以囊括一下我们现在人工智能方向主要的工作,其实人工智能是一个非常基础的技术,我在这张图里面大概做了一个概括。这里面可以看到分成三个层次,第一个层次在底层是平台层,包括深度学习的一个平台。中间这个层次是能力层,云的技术、自然语言处理的技术、智能头像处理的技术。第三个是应用层,应用在网易云、游戏、有道翻译等产品里面,对公司来讲我们从三个层面,从品牌、能力最后到应用的场景,今天主要从中间的能力层展开来讲。
第一块是语音技术。网易在语音技术上为了去解决超大规模的、上万个小时的语音训练问题,我们在云这一块就把深度学习的一个平台的技术带动出来了。
我们大概是在13年的时候开始做语音识别,网易在现在所有的游戏、社交、易信这些产品里面都是采用我们自研的语音技术。具体的应用场景最主要的是在手游里面使用量非常大,每天的处理请求量达到五千万,根据公开的一个数据来看,这个量达到苹果系统的1/3左右。
这里面我想突出说一点,这一点也是我们对人工智能在工程领域应用的一个核心认识:所有的人工智能这些能力从语音到图象到自然语音理解,其实它都没有办法提供一个非常通用的至尊全讯大全官网的解决方案。
所以在语音识别我们一开始用的是通用的,后来觉得在游戏里面效果不太理想的,游戏里面涉及到太多跟游戏世界观相关的词汇,还有游戏里面特殊的一些词。所以我们在自研的过程中针对游戏特定的世界观进行优化,获得比一个通用的云识别要高一两个点的效果。这个也是我们在实际的场景里面会不断的去发现问题。一个通用的人工智能能力它在应用到特定的场景里面的时候,可能达不到一个很好的使用效果。
另外一个我们在做的事情,就是发音评测的工作,主要应用在我们有道翻译里面。
第二块是自然语言理解方面做的工作,这边有一些例子,对于自然语言理解,我们现在主要做的工作是用在客服机器人的应用场景里面。
这边举了一些客服机器人的案例。对一个客服机器人来讲,传统来讲,它是一个知识库的一个检索的问题,传统方式并不是一个人工智能的至尊全讯大全官网的解决方案。这个用户体验也是很差的。所以现在你如果要提供一个用户体验比较好的客服机器人,那它需要支持比较智能的多轮对话的方式。人跟人之间的对话不是说直接一问一答问题就解决了,它是需要机器人能够了解到这个领域的知识。我举个例子,比如我要打车,我说我要打车到浙大紫金港校区,他应该知道浙大紫金港校区是有东门、南门的,它会追问请问你到哪个门,因为这是两个不同的点,这个其实就涉及到领域的知识。
我很难具体来讲怎么样从技术上、细节上做到这一点,总体来讲对于大家做客服机器人,首先要有一种方式解决多轮对话的问题,这里面可能会涉及到m的机制、a的机制,同时也要解决领域知识的一些问题。这里面就需要用到比如说知识图谱的方式,还需要针对特定的一个行业去做定制。我们做的像知识库的一个动态学习,那这个机制是为了能够提高知识库学习的效率,但是并没有一个特别通用的方案可以客服机器人一下能够无所不能,能够回答所有的问题,这是不现实的。
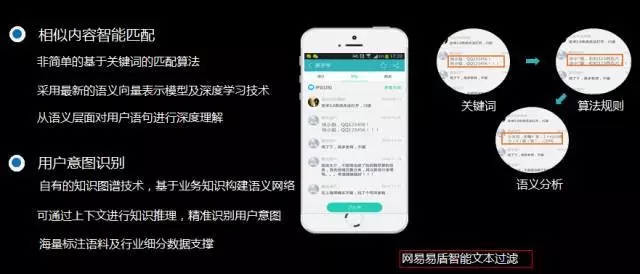
这个是文本过滤。我们的网易新闻有一个很好的功能叫跟贴,跟贴其实就是用户发表评论,我们把它设计成盖楼的方式,但这个评论里面会涉及到非常多垃圾有害信息。我们的人工智能技术也会用在这里。ugc的产品里面大量的用户评论容易产生不恰当的地方,传统的关健词过滤技术解决不了复杂的垃圾变化,比如拆字,各种组合方式。这时候,通过自然语言理解,通过深度学习的方式能够做到比较好的效果。
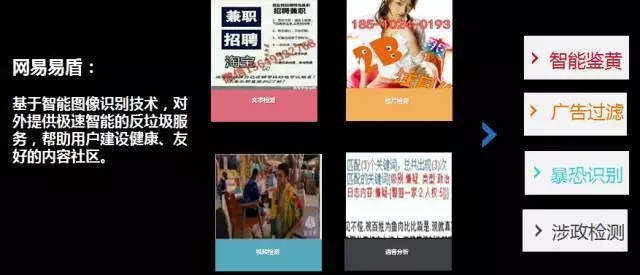
第三块智能图象识别。智能图象识别它的主要应用场景跟刚才说的文本的识别、文本的过滤是类似的。我们有很多产品里面用户会晒图,这个图片是不是有不合适的内容,里面有爆恐的、不良广告或者色情的图像,传统的方式也解决不了,但是现在通过深度学习的方式也可以做到非常好的,非常精准的效果。
对于色情图片,对于图片鉴黄,从06年我开始做研究院工作,06年我们的鉴黄师用什么来做的?在一个小黑屋养一堆鉴黄师,那时候量比较少,很辛苦也很幸福。那个时候如果用算法判断,实际上是很困难的,比如用简单的一些肤色识别方式是很麻烦的。稍微做一些编辑你又被它逃掉了,而且你的库不可能非常全面准确。所以它的准确率只有5%。
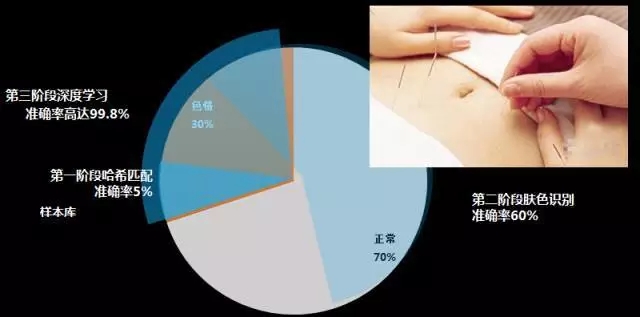
第二个阶段通过肤色识别,准确率只能做到60%,基本上处于不可用的状态,还有40%是错误的,60减40就剩20%,这个技术基本上没有用。
直到第三代深度学习的做法才做到99.8%这样非常高的准确率。同时,我们还会用机器加人工智能的方式避免误判。这个技术我们现在提供对外的服务,叫网易易盾。
后面说一下我们未来想做的事情,第一个进一步加强人工智能的深度学习平台,因为我们现有非常多的应用都需要用到深度学习。几乎每过一年都会发现很多算法会被深度学习代替。比如我们现在在做基于深度学习的翻译,翻译效果比原来统计的翻译效果会好很多。对于网易来讲现在有近万名的开发工程师,这里面有很多的工程师可能就需要用到机器学习,用到深度学习解决很多问题。我们必须把这个机器学习的能力普及化,让大家一些普通的工程师,前期比较优秀的工程师都能够使用这么一个工具,所以我们会去做一个深度学习的很便捷的机器学习平台,这个对于网易来讲是一个非常基础的工作。
第二个我们希望在语音识别、图像识别、智能创作这些更多的领域来去深入应用深度学习技术。