易盾数字内容风控时刻关注最新舆情,覆盖全网资讯数据。然而,原始数据格式各式各样,舆情监测平台如何将海量原始数据转换为统一的数据格式成为数据处理前置条件。
舆情数据清洗主要面临如下几个难点:
○全网数据格式多种多样,如何快速相应新数据接入,同时不影响架构的“开闭原则”?
○如何协调爬虫、etl、研发三方的协作与数据流通?
○如何让数据清洗满足灵活性的同时,保证其清洗性能?
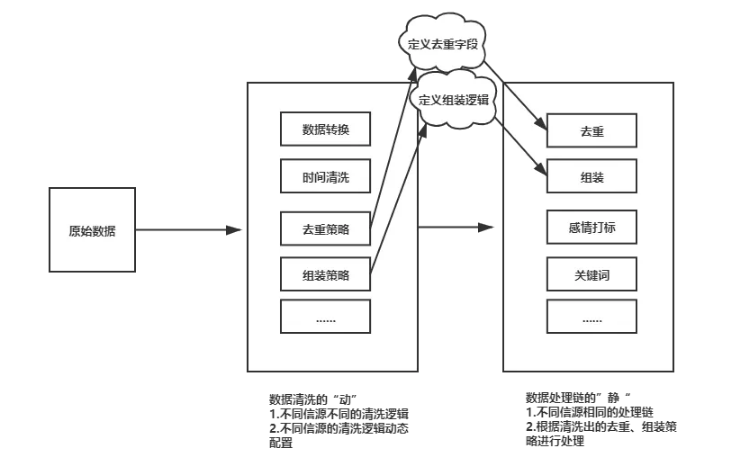
01 业务架构上“动”、“静”分离
基于上述分析,我们仔细分析整个数据处理链中的各环节,挖掘出各模块的处理逻辑本质,进行动静分类。比如将灵活性较高的分类为“动”的部分,将固定逻辑的分类为“静”的部分,这样两者各司其职、互不干扰。如下图所示:
○人员职能上,etl与系统开发分离,制定清洗流程规范
○清洗脚本动态可配置,实现新数据源接入实时化
○支持数据清洗链,合理管理清洗脚本,各清洗脚本可相互复用
○静态模块(去重、组装),根据动态清洗结果,选择相应的数据处理策略
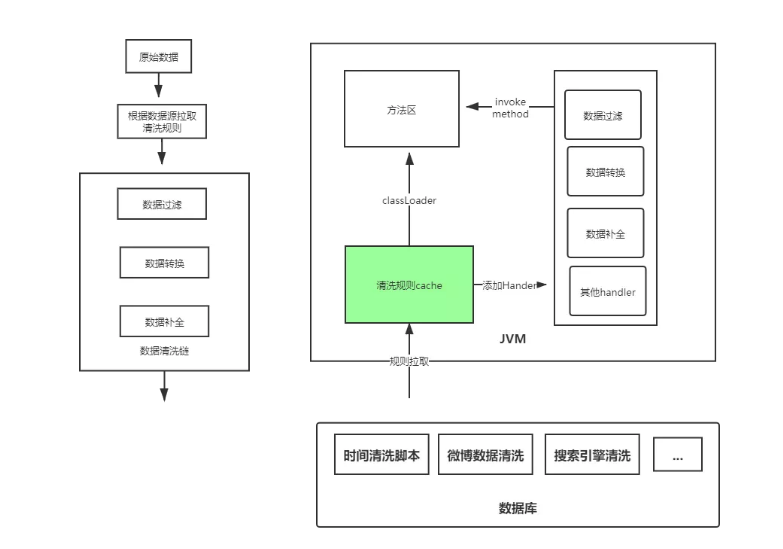
02 数据清洗的“动”
基于上面的问题和思考,易盾舆情搭建了脚本可配置的数据清洗平台,制定数据清洗流程,实现新数据源实时接入。该方案具有如下几个特点:业务架构上动静分离、技术架构上高性能、可扩展、高可用。
具体来说,基于groovy脚本,结合jvm动态类加载,将groovy脚本动态加载、内化为jvm中普通function甚至可以利用jit优化加速清洗逻辑执行速度,从而保证数据清洗整体性能。多节点部署,保证整体处理吞吐量,高可用、可扩展。
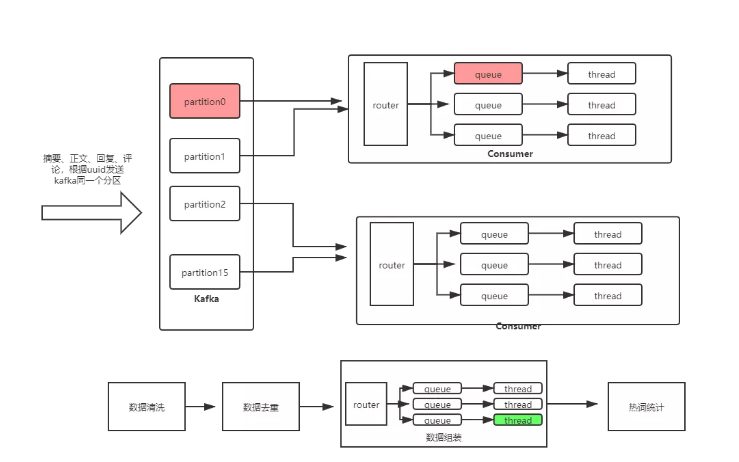
03 数据处理链的“静”
对爬虫的原始数据,做一系列处理,如图去重、感情打标、数据组装、关键词提取等。如上文所示,由于数据清洗模块将不同信源数据转成统一格式,同时通过设置去重字段、组装策略等方法,“告诉”处理链该如何处理这些数据。因此,数据处理链可以不需要针对不同信源定制化处理逻辑,实现数据处理链的“静”。如下所示,数据处理链主要包括如下两点:
一、根据数据清洗出的去重策略、组装策略,执行相应的数据处理逻辑。
二、基于自研路由线程组,结合kafka分区顺序性,保证数据消费顺序性,实现数据顺序组装对爬虫数据合理分片路由,保证数据顺序性、并行性,兼顾处理性能与数据处理正确性。
04 总结
基于groovy类脚本,结合jvm动态类加载,保证数据清洗灵活性与高性能。多节点部署,保证整体处理吞吐量,高可用、可扩展。从而实现业务架构上“动”、“静”分离,技术架构上高性能、可扩展、高可用。最终实现新数据源实时接入,提高舆情系统数据处理的相应速度。